Structur2Vec+DQN[2017 ] Learning Combinatorial Optimization Algorithms over Graphs
This paper is 2017 NIPS. One of the improtant researchers is Bistra Dilkina, from USC.
Furthermore, existing works typically use the policy gradient for training [6], a method that is not particularly sample-efficient.
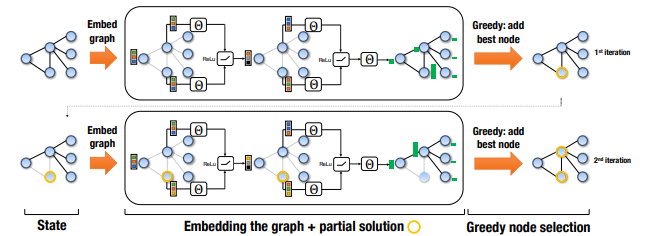
They used a single meta-learning algorithm, efficiently learns effective heuristics for each of the problems. They solve three problem: Minimum Vertex Cover (MVC), Maximum Cut (MAXCUT) and Traveling Salesman Problem (TSP). They use a greedy algorithm to solve the probem. A greedy algorithm will construct a solution by sequentially adding nodes to a partial solution S, based on maximizing some evaluation function Q that measures the quality of a node in the context of the current partial solution. A maintenance (or helper) procedure h(S) will be needed, which maps an ordered list S to a combinatorial structure satisfying the specific constraints of a problem. The quality of a partial solution S is given by an objective function based on the combinatorial structure of .
A generic greedy algorithm selects a node v to add next such that v maximizes an evaluation
function,
, which depends on the combinatorial structure of the current
partial solution. Then, the partial solution
will be extended as
MVC: The helper function does not need to do any work, and The termination
criterion checks whether all edges have been covered.
MAXCUT: The helper function divides V into two sets, S and its complement , and maintains a cut-set . Then, the cost is , and the termination criterion is activated when . Empirically, inserting a node u in the partial tour at the position which increases the tour length the least is a better choice. We adopt this insertion procedure as a helper
function for TSP
structure2vec
They used the idea of this paper
This graph embedding network will compute a p-dimensional feature embedding for each node , given the current partial solution . One variant of the structure2vec architecture will initialize the embedding at each node as 0, and for all update the embeddings synchronously at each iteration as
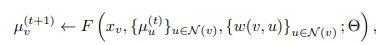
where is the set of neighbors of node v in graph G, and F is a generic nonlinear mapping such as a neural network or kernel function.
Parameterizing Q function
design F to update a p-dimensional embedding as
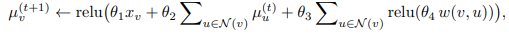
The summation over neighbors is one way of aggregating neighborhood information that is invariant to permutations over neighbors.
Once the embedding for each node is computed after T iterations, we will use these embeddings to define the
is the concatenation operator
Training RL
Actions: an action v is a node of G that is not part of the current state S. Similarly, we will represent actions as their corresponding p-dimensional node embedding µv, and such a definition is applicable across graphs of various sizes;
Rewards: the reward function at state S is defined as the change in the cost function after
taking action v and transitioning to a new state
. That is
Policy: based on Qb, a deterministic greedy policy will be
used.

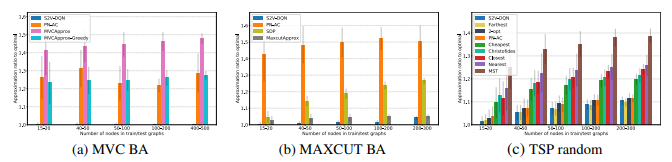
Experiment
